The DARE Platform
The latest version (v3.6) of the DARE Platform has been released.
Visit the dedicated DARE platform website for all latest releases
The DARE platform provides all the necessary tools to research developers to develop and execute their experiments written using the fine-grained workflow specification library dispel4py. Moreover, the DARE platform offers data provenance to the users so as to track and analyze their data. The architecture below lays out the architecture of the DARE platform.
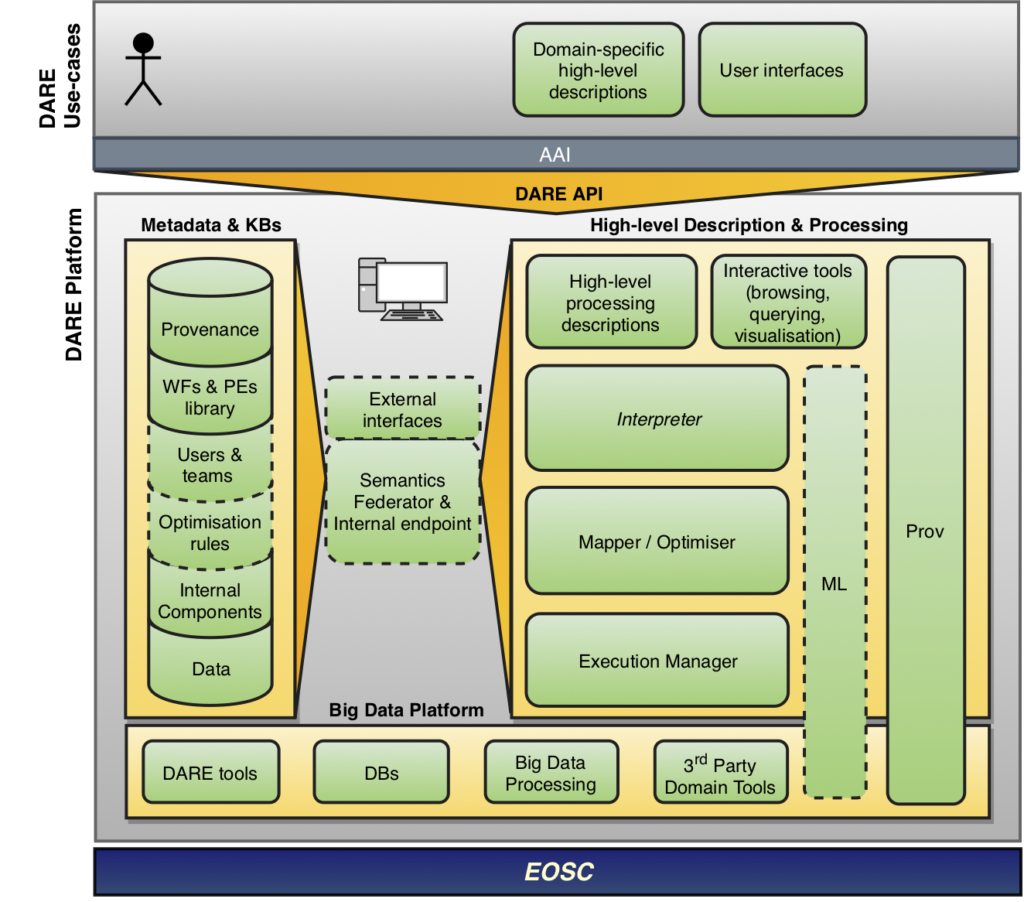
The DARE platform is cloud-ready, integrating containerized software applications running on top of Kubernetes. Kubernetes enables automated deployment, scaling and management of containerized applications.
Research developers can interact with the DARE platform by making use of its RESTful API. DARE API is a composition of RESTful Web APIs exposed by the containerized versions of the underlying DARE platform components.
The main DARE components, currently available in the platform, are:
– The Execution API and PEs library API which allows the Workflows-as-a-Service functionality
– s-provflow that provides Provenance
– Execution API, which is responsible for the distributed and scalable execution of Dispel4Py workflows or Specfem3D simulations
– Playground testing environment.
The core components that will be extended, improved and ultimately incorporated in the DARE hyper-platform are available here: https://project-dare.gitlab.io/dare-platform